
Das Problem hinter unstrukturierten Lieferantendaten
Wer mit vielen Lieferanten arbeitet, kennt die Situation. Einer liefert eine Excel-Datei mit 40 Spalten - aber anderen Spaltennamen als das eigene PIM. Der nächste schickt einen PDF-Katalog mit zehn Seiten pro Produkt. Ein anderer sendet Produktfotos als ZIP, dazu eine Word-Datei mit technischen Angaben.
Ergebnis: Jemand im Team muss die Daten manuell lesen, übertragen und eintippen. Pro Produkt dauert das Minuten. Bei 2.000 neuen Produkten im Jahr summiert das sich auf Wochen Arbeit.
Das Kernproblem ist nicht das Format. Das Kernproblem ist, dass unstrukturierte Quellen einen manuellen Zwischenschritt erzwingen - bevor die eigentliche Aufbereitung überhaupt beginnt. Wie viel das kostet, haben wir in unserem Artikel zu den echten Kosten der Produktdatenpflege durchgerechnet.
Der häufigste Engpass im Daten-Onboarding ist nicht das PIM-System. Es ist der Schritt davor: das manuelle Lesen und Übertragen unstrukturierter Lieferantendaten.
Was KI aus PDFs und Bildern lesen kann
Moderne KI-Systeme können unstrukturierte Quellen direkt verarbeiten. Das heißt in der Praxis:
- PDF-Kataloge: Die KI erkennt Produktblöcke, liest Bezeichnungen, Maße, Materialien und Attribute - auch ohne einheitliches Layout.
- Produktfotos: Farbe, Oberfläche, Produktart und sichtbare Attribute werden direkt aus dem Bild abgeleitet.
- Gescannte Tabellen: OCR extrahiert Text und Zahlen, auch aus qualitativ mittlemäßigen Scans.
- Unstrukturierte Textfelder: Attribut-Werte werden aus Freitext rekonstruiert. Zum Beispiel wird "MDF und Spanplatte" im Quellformat automatisch dem Zielwert "Holzwerkstoff" zugeordnet.
- Gemischte Dateipakete: PDF, JPG, CSV und Excel lassen sich in einem Durchlauf verarbeiten - ohne separate Konfiguration pro Format.
Das Ergebnis ist ein strukturierter Datensatz mit befüllten Attributen, normalisierten Werten und einer einheitlichen Datenstruktur. Kein manuelles Eintippen mehr.
Von der Datei zum fertigen Produktdatensatz
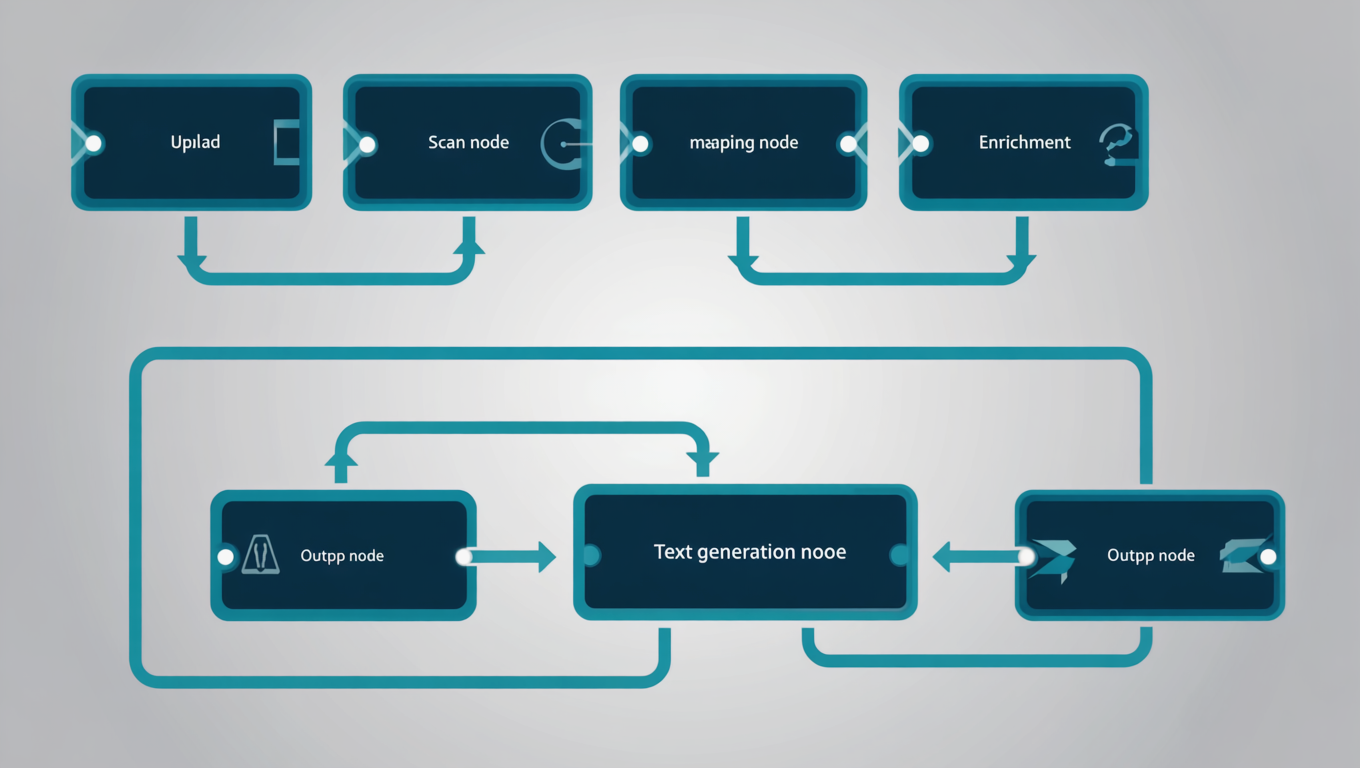
Der Prozess läuft vollständig automatisch:
- Datei hochladen - PDF, JPG, CSV, Excel: die Plattform nimmt jedes Format entgegen.
- Erkennung und Extraktion - Die KI liest die Inhalte, identifiziert Produkte und extrahiert Attribute aus der jeweiligen Quelle.
- Mapping und Bereinigung - Extrahierte Werte werden auf das Zielformat gemappt. Inkonsistente Bezeichnungen, fehlende Einheiten und doppelte Felder werden normalisiert.
- Anreicherung - Fehlende Attribute werden durch Online-Recherche oder vorhandene Katalogdaten ergänzt.
- Textgenerierung - Aus den strukturierten Daten entstehen SEO-optimierte Beschreibungen, Bullet Points und Meta-Texte - in der Zielsprache des Kanals.
- Ausgabe - Der fertige Datensatz wird im Zielformat ausgegeben, direkt bereit für PIM, Shopify, Amazon oder einen anderen Marktplatz.
Was früher ein ganzer Arbeitstag war, dauert so oft wenige Minuten. Wie das automatische Mapping ohne manuelle Regeln funktioniert, beschreiben wir ausführlich im Artikel über 100 Lieferantenformate automatisch ins PIM mappen.
Was das konkret für dein Team bedeutet
Für ein Unternehmen mit vielen Lieferanten bedeutet das: Die Qualität und das Format der eingehenden Daten spielen keine Rolle mehr. Egal ob ein Lieferant einen sauberen CSV-Export liefert oder nur einen Scan aus dem Drucker - der Aufwand für das Team bleibt derselbe.
Der einzige manuelle Schritt, der bleibt, ist die Endkontrolle. Nicht das Eintippen. Nicht das Mappen. Nicht das Formulieren. Nur das Abnicken - oder das Anpassen einzelner Ausnahmen.
Für Teams, die heute noch Stunden pro Lieferant verbringen, ändert sich damit die Grundlage. Neue Produkte kommen früher online. Das Sortiment wächst schneller. Was Time-to-Market dabei wirklich entscheidet, haben wir in Wer zuerst listet, gewinnt beschrieben.
Fazit
Unstrukturierte Lieferantendaten sind kein Ausnahmeproblem - sie sind der Alltag. Katalog-PDFs, Produktfotos, gescannte Listen: fast jedes Unternehmen hat mindestens einen Lieferanten, der keine saubere Excel-Datei liefert.
Eine KI-Plattform, die PDFs und Bilder direkt verarbeitet, macht den manuellen Zwischenschritt überflüssig. Der Aufwand sinkt. Die Verarbeitungsgeschwindigkeit steigt. Und das Team kann sich um Aufgaben kümmern, bei denen menschliches Urteil tatsächlich gefragt ist.
Häufige Fragen
Welche Dateiformate kann die KI verarbeiten?
Die KI verarbeitet gängige Formate wie PDF, JPEG, PNG und gescannte Dokumente - auch wenn diese nicht maschinenlesbar sind. Strukturierte Formate wie Excel, CSV oder XML werden ebenfalls automatisch erkannt und verarbeitet. Entscheidend ist nicht das Format, sondern der Inhalt.
Wie genau extrahiert KI Produktdaten aus Bildern und PDFs?
Moderne KI kombiniert Texterkennung (OCR) mit inhaltlichem Verständnis. Das bedeutet: Sie erkennt nicht nur Text, sondern versteht, welche Information welchem Produktattribut entspricht - auch ohne einheitliche Struktur. Die Genauigkeit liegt in der Praxis bei über 95 Prozent.
Was passiert bei schlechter Scan-Qualität oder handschriftlichen Notizen?
Kein Problem für 2txt. Schlechte Scans, geringe Auflösung, handschriftliche Notizen - die KI kommt damit zurecht. Entscheidend ist der Inhalt, nicht die Aufbereitungsqualität. Auch Lieferantendokumente, die intern als "unleserlich" gelten, werden zuverlässig verarbeitet.
Muss jedes Lieferanten-PDF einzeln eingerichtet werden?
Nein. Das ist der Kernunterschied zu regelbasierten Systemen. KI erkennt neue Dokumentstrukturen automatisch - ohne vorherige Konfiguration. Für automatisiertes Produktdaten-Onboarding mit 2txt wird kein Template pro Lieferant gepflegt.
In welchen Sprachen funktioniert die Daten-Extraktion?
Die Extraktion funktioniert sprachunabhängig - relevante Attributwerte (Maße, Gewichte, Materialien, Farben) werden erkannt, unabhängig davon, ob das Dokument auf Deutsch, Englisch, Französisch oder einer anderen Sprache vorliegt.
Wir zeigen dir in einer Demo, wie 2txt dein Format verarbeitet - egal in welcher Form es ankommt. Keine Folien, keine Theorie.
Weitergelesen: PIM löst kein Datenchaos - was wirklich beim Onboarding hilft · Produktdaten-Onboarding automatisieren mit 2txt
Zurück zum Blog